

La génération de texte à image grâce à l’IA
Définition des modèles de génération d’image
Les modèles de texte à image sont des modèles génératifs utilisant l’intelligence artificielle pour produire des images à partir de descriptions écrites, appelées « prompts ». Ces modèles sont de plus en plus populaires en raison de leur potentiel à générer des images créatives et originales. Les données visuelles utilisées pour l’entraînement de ces modèles sont collectées à partir de sources diverses, notamment à partir d’œuvres d’art, de photographies et d’images en ligne.
Quels sont les principaux acteurs ?
Le domaine de la génération d’images est en constante évolution et trois acteurs majeurs y jouent un rôle prépondérant.
- • DALL-E 2 d’OpenAI, la première organisation à avoir fait une démonstration grand public de cette technologie
- • Midjourney, un laboratoire de recherche indépendant offrant une option gratuite d’utilisation du modèle sur le logiciel Discord.
- • Stable Diffusion de StabilityAI, une initiative open-source qui diffuse régulièrement les dernières mises à jour de son modèle.
Ces trois acteurs sont à la pointe de la technologie pour la génération d’images et continuent de pousser les limites de celle-ci. Tous utilisent une technique appelée « diffusion latente » que nous creuserons plus en détail plus loin. Cependant, l’idée derrière cette méthode est d’apprendre à un modèle à recréer des formes familières dans un champ de bruit pur. Ces formes sont modelées progressivement en si elles correspondent aux mots dans le “prompt” grâce à un mécanisme d’attention.

Intuition derrière la génération d’image
Une analogie pour comprendre la tâche que les ordinateurs tentent d’accomplir peut-être exprimée en examinant le raisonnement d’un.e artiste lorsqu’on lui demande de dessiner une oeuvre d’art. Dans ce scénario, nous fournissons à un.e artiste une description plus ou moins précise des caractéristiques de l’objet que nous souhaitons voir dessiner. Ensuite, l’artiste utilise son imagination pour concevoir la manière dont il peut représenter l’objet. Finalement il peut s’exécuter et produire l’oeuvre finale.
Les modèles de génération d’images en intelligence artificielle tentent d’automatiser cette tâche en utilisant le modèle appelé “Transformers” pour générer des images à partir de descriptions textuelles.
Principe de la diffusion
La modélisation générative par diffusion est une technique puissante en intelligence artificielle pour générer des images à partir de bruit pur. Ce processus implique l’application d’un débruitage itératif, à partir d’une image bruitée. En d’autres termes, le modèle apprend à reconnaître des formes familières dans un champ de bruit pur, puis affine progressivement ces éléments s’ils correspondent aux contextes donnés en entrée.
Ce processus de débruitage peut être conditionné avec une image en plus d’une image bruitée en entrée. Cette méthode de conditionnement permet au modèle de tenir compte des informations supplémentaires fournies par l’image, pour produire des images plus précises.
En outre, le processus de débruitage peut également être conditionné avec du texte, ce qui est l’essence du modèle texte à image que nous avons déjà introduit. Cette technique permet de générer des images à partir de descriptions textuelles en utilisant un processus similaire de débruitage itératif.

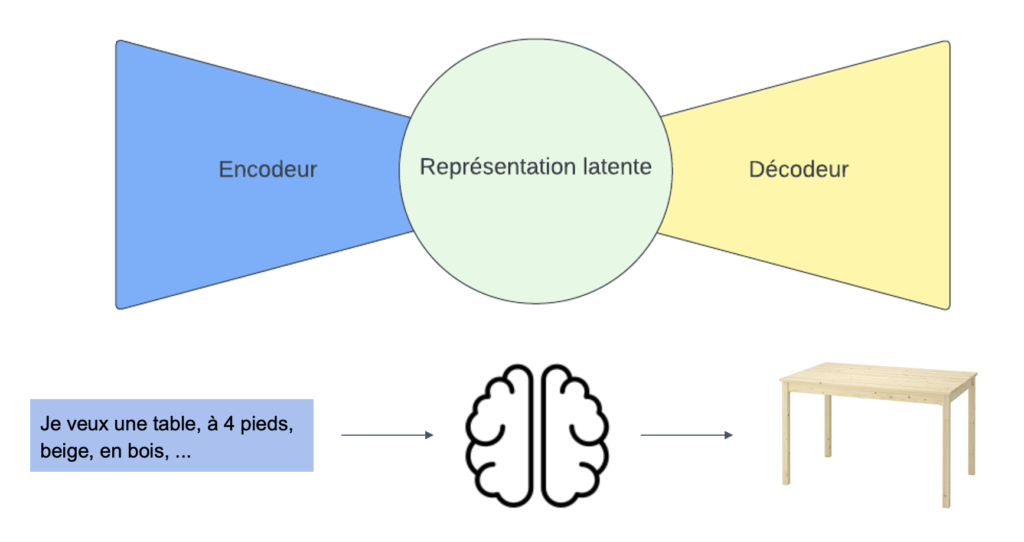
Principe de la diffusion latente
Les modèles de diffusion latente sont des modèles de diffusion qui au lieu de travailler directement avec une image telle quelle utilisent une représentation de l’image compressée appelée « représentation latente ». L’utilisation de représentations latentes dans les modèles de diffusion permet à ceux-ci de travailler plus efficacement avec des données visuelles ou textuelles, en comprimant l’information en un espace plus petit, tout en préservant les informations clés. De plus, l’utilisation d’une telle méthode conduit à des performances améliorées quant aux temps et aux ressources informatiques nécessaires à la génération d’image.
Travailler dans un espace aussi compressé permet également d’utiliser différents types de données, telles que le texte. Ces représentations peuvent être injectées dans les couches d’attention, qui sont les composants clés des modèles Transformers. Les couches d’attention permettent au modèle d’identifier les parties importantes de l’image ou du texte en entrée, en concentrant son attention sur les zones les plus pertinentes et ainsi générer l’image adéquate.
Mécanisme de la diffusion latente
Pendant le processus d’inférence, le modèle associe des mots avec des images en utilisant une technique appelée CLIP (Contrastive Language-Image Pre-training), qui a été développée par OpenAI. Ce modèle cherche à produire en sortie un vecteur correspondant à l’information latente dans le “prompt” pour aider le processus de débruitage. Une fois ce vecteur produit, celui-ci est passé à travers un réseau de neurones appelé U-Net. Celui-ci est un type spécial de réseau de neurones convolutifs (CNN) d’image à image, utile pour le débruitage itératif. Ainsi, ce réseau de neurones partant de bruit et conditionné avec l’information latente contenu dans le “prompt” dé-bruite progressivement la représentation latente de l’image à générer. Finalement, une fois cette représentation latente dé-bruiter, celle-ci est passée à travers un décodeur pour produire l’image finale.
Importance du prompt engineering
Comme tout modèle génératif, le prompt engineering est une partie importante pour conditionner correctement l’image que l’on souhaite générer. Voici par exemple quelques éléments importants à inclure dans un “prompt” destinés à la génération d’images :
- • Noms des objets : Spécifier les objets que l’on souhaite inclure dans l’œuvre
- • Adjectifs : Utiliser des adjectifs pour décrire le style, la couleur et la qualité de l’œuvre.
- • Noms d’artistes : Calquer le style d’un.e artiste en particulier.
- • Style artistique : Calquer un style artistique, comme « pixel-art », « fantaisie », « surréalisme », « contemporain »
- • Qualité : Spécifier la qualité de l’image, comme « haute qualité », « 4k » ou « 8k »
Cette liste n’est pas exhaustive et il existe d’autres techniques plus avancées pour utiliser ces outils.
Affinage d’un modèle pour un usage artistique
Les modèles de diffusions stables peuvent être, comme les autres types de modèles de fondation, affinés pour effectuer une tâche en particulier. Dans le cas du texte à image, cela peut être très pertinent si l’on veut explorer certaines possibilités artistiques tout en suivant le style graphique de personnage déjà existant.
Nous pouvons illustrer cette adaptation en faisant apprendre à notre modèle par exemple le style graphique des Pokémon. En ajoutant des “prompts” associées à chaque Pokémon, il est ainsi possible de demander au modèle de générer de nouvelles créatures.

Exemple d’autres usages
En plus de sa fonction de base, qui permet de créer des images à partir de texte, la diffusion stable a d’autres cas d’utilisation passionnants.
L’un de ces cas est la retouche d’images. En effet, grâce à une technique d’outpainting, la diffusion stable peut être utilisée pour restaurer des images endommagées en recréant les parties manquantes à l’aide de l’IA. Il est également possible, en utilisant une technique d’inpainting, d’intégrer des éléments à l’intérieur d’une image pour améliorer son apparence.
Dans le futur, il sera possible à partir de texte de générer et non plus seulement des images, mais également des contenus vidéo. Cette fonctionnalité révolutionnaire a été en effet démontrée par l’entreprise Meta vers la fin de l’année 2022.

Considération éthique
Bien que les possibilités de l’utilisation de cet outil sont impressionnantes. Celui-ci soulève plusieurs préoccupations éthiques et légales, notamment autour de la propriété intellectuelle.
Par exemple, bien que l’outil dispose d’un filtre pour bloquer les images inappropriées, il peut être facilement contourné, ce qui peut causer des problèmes pour la protection de la vie privée et la sécurité en ligne.
De plus, l’utilisation de l’outil pour imiter le style d’artistes existants peut soulever des questions sur la propriété intellectuelle et les droits d’auteur. Par exemple, le 26 août 2022, une œuvre générée par une intelligence artificielle a gagné un concours de beaux-arts au Colorado aux États-Unis. Ce scandale a permis de nous rappeler que l’influence de ces outils dans le milieu artistique est disruptive et ne doit pas être prise à la légère.
Enfin, les images réalistes créées par cet outil peuvent être utilisées à des fins dangereuses, telles que la propagande ou la désinformation. En effet, ces images peuvent être utilisées pour usurper l’identité de quelqu’un, ce qui peut causer de gros problèmes éthiques. Dans le futur il sera donc important de mettre en place des systèmes de vérification pour s’assurer que les images générées soient authentiques.
Tags:
- Midjourney
16
MarDéfinition des modèles de génération d’image Les modèles de texte à image sont des modèles génératifs utilisant l’intelligence artificielle pour produire des images à partir de descriptions écrites, appelées « prompts ». Ces modèles sont de plus en plus populaires en raison de leur potentiel à générer des images créatives et originales. Les données visuelles utilisées pour l’entraînement de ces modèles sont collectées à partir de sources diverses, notamment à partir d’œuvres d’art, de photographies et d’images en ligne. Quels sont les principaux acteurs ? Le domaine de la génération d’images est en constante évolution et trois acteurs majeurs y jouent un rôle prépondérant. • DALL-E 2 d’OpenAI, la première organisation à avoir fait une démonstration grand public de cette technologie • Midjourney, un laboratoire de recherche indépendant offrant une option gratuite d’utilisation du modèle sur le logiciel Discord. • Stable Diffusion de StabilityAI, une initiative open-source qui diffuse régulièrement les dernières mises à jour de son modèle. Ces trois acteurs sont à la pointe de la technologie pour la génération d’images et continuent de pousser les limites de celle-ci. Tous utilisent une technique appelée « diffusion latente » que nous creuserons plus en détail plus loin. Cependant, l’idée derrière cette méthode est d’apprendre à un modèle à recréer des formes familières dans un champ de bruit pur. Ces formes sont modelées progressivement en si elles correspondent aux mots dans le “prompt” grâce à un mécanisme d’attention. Intuition derrière la génération d’image Une analogie pour comprendre la tâche que les ordinateurs tentent d’accomplir peut-être exprimée en examinant le raisonnement d’un.e artiste lorsqu’on lui demande de dessiner une oeuvre d’art. Dans ce scénario, nous fournissons à un.e artiste une description plus ou moins précise des caractéristiques de l’objet que nous souhaitons voir dessiner. Ensuite, l’artiste utilise son imagination pour concevoir la manière dont il peut représenter l’objet. Finalement il peut s’exécuter et produire l’oeuvre finale. Les modèles de génération d’images en intelligence artificielle tentent d’automatiser cette tâche en utilisant le modèle appelé “Transformers” pour générer des images à partir de descriptions textuelles. Principe de la diffusion La modélisation générative par diffusion est une technique puissante en intelligence artificielle pour générer des images à partir de bruit pur. Ce processus implique l’application d’un débruitage itératif, à partir d’une image bruitée. En d’autres termes, le modèle apprend à reconnaître des formes familières dans un champ de bruit pur, puis affine progressivement ces éléments s’ils correspondent aux contextes donnés en entrée. Ce processus de débruitage peut être conditionné avec une image en plus d’une image bruitée en entrée. Cette méthode de conditionnement permet au modèle de tenir compte des informations supplémentaires fournies par l’image, pour produire des images plus précises. En outre, le processus de débruitage peut également être conditionné avec du texte, ce qui est l’essence du modèle texte à image que nous avons déjà introduit. Cette technique permet de générer des images à partir de descriptions textuelles en utilisant un processus similaire de débruitage itératif. Principe de la diffusion latente Les modèles de diffusion latente sont des modèles de diffusion qui au lieu de travailler directement avec une image telle quelle utilisent une représentation de l’image compressée appelée « représentation latente ». L’utilisation de représentations latentes dans les modèles de diffusion permet à ceux-ci de travailler plus efficacement avec des données visuelles ou textuelles, en comprimant l’information en un espace plus petit, tout en préservant les informations clés. De plus, l’utilisation d’une telle méthode conduit à des performances améliorées quant aux temps et aux ressources informatiques nécessaires à la génération d’image. Travailler dans un espace aussi compressé permet également d’utiliser différents types de données, telles que le texte. Ces représentations peuvent être injectées dans les couches d’attention, qui sont les composants clés des modèles Transformers. Les couches d’attention permettent au modèle d’identifier les parties importantes de l’image ou du texte en entrée, en concentrant son attention sur les zones les plus pertinentes et ainsi générer l’image adéquate. Mécanisme de la diffusion latente Pendant le processus d’inférence, le modèle associe des mots avec des images en utilisant une technique appelée CLIP (Contrastive Language-Image Pre-training), qui a été développée par OpenAI. Ce modèle cherche à produire en sortie un vecteur correspondant à l’information latente dans le “prompt” pour aider le processus de débruitage. Une fois ce vecteur produit, celui-ci est passé à travers un réseau de neurones appelé U-Net. Celui-ci est un type spécial de réseau de neurones convolutifs (CNN) d’image à image, utile pour le débruitage itératif. Ainsi, ce réseau de neurones partant de bruit et conditionné avec l’information latente contenu dans le “prompt” dé-bruite progressivement la représentation latente de l’image à générer. Finalement, une fois cette représentation latente dé-bruiter, celle-ci est passée à travers un décodeur pour produire l’image finale. Importance du prompt engineering Comme tout modèle génératif, le prompt engineering est une partie importante pour conditionner correctement l’image que l’on souhaite générer. Voici par exemple quelques éléments importants à inclure dans un “prompt” destinés à la génération d’images : • Noms des objets : Spécifier les objets que l’on souhaite inclure dans l’œuvre • Adjectifs : Utiliser des adjectifs pour décrire le style, la couleur et la qualité de l’œuvre. • Noms d’artistes : Calquer le style d’un.e artiste en particulier. • Style artistique : Calquer un style artistique, comme « pixel-art », « fantaisie », « surréalisme », « contemporain » • Qualité : Spécifier la qualité de l’image, comme « haute qualité », « 4k » ou « 8k » Cette liste n’est pas exhaustive et il existe d’autres techniques plus avancées pour utiliser ces outils. Affinage d’un modèle pour un usage artistique Les modèles de diffusions stables peuvent être, comme les autres types de modèles de fondation, affinés pour effectuer une tâche en particulier. Dans le cas du texte à image, cela peut être très pertinent si l’on veut explorer certaines possibilités artistiques tout en suivant le style graphique de personnage déjà existant. Nous pouvons illustrer cette adaptation en faisant apprendre à notre modèle par exemple le style graphique des Pokémon. En ajoutant des “prompts” associées à chaque Pokémon, il est ainsi possible de ...
16
Mar